A little more than two years ago Lucas Systems introduced a new voice/speech recognition platform – Serenade – that combines the advantages of speaker-dependent and speaker-independent speech recognition systems in a single product. Besides industry-best recognition accuracy in challenging warehouse environments, with Serenade users can start using the voice system after completing a short enrollment process, as compared to a 30 minute voice training process required with traditional voice picking systems.
To understand the advantages of Serenade, its useful to look at the pros and cons of speaker-dependent technology that dominates the warehouse market today, as well as of speaker-independent technologies that are more prevalent in consumer, call center, and other markets. Consumer speech recognition is a rich target for comedy. See some funny speech-related videos on the Lucas YouTube channel.
Dependent Systems Require Training and Re-training
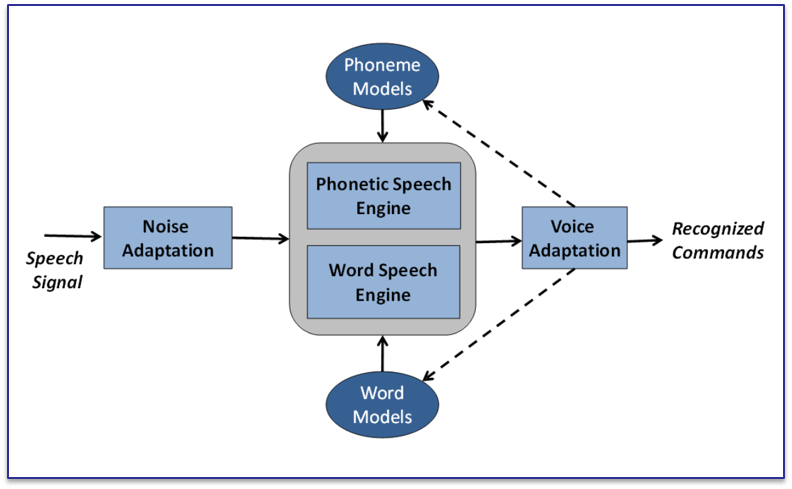
Until recently warehouse voice systems used speaker-dependent technology in which the voice engine is tuned to recognize each user’s speech patterns. Those systems required a 20-30 minute “voice training” process for each user. This half hour training step is seen as a small price to pay to get near-perfect recognition accuracy. One shortcoming of most first generation speaker dependent systems was that they often required users to record a second voice template after starting to work with the system. Why? Because people usually speak very clearly and deliberately when they initially create their voice template, but as they get comfortable working with voice, they speed up and revert to their usual speech patterns. When that happens, the recognizer starts having problems matching what they say against the template they built, so the user will retrain.
To eliminate the need to retrain, Lucas introduced the concept of adaptive voice modeling, in which the speech software automatically adapts the user’s voice template in the course of use. So as users start working faster, slurring words together and cutting off the ends of words, the recognizer keeps up. More importantly, rather than degrading, recognition accuracy actually improves with use, even when a user comes down with a cold.
Independent Systems Don’t Adapt Well to Individuals
What if you could do away with training altogether so that anyone could use the system without creating a voice model? That’s the advantage of speaker-independent systems used in automated customer service applications and other consumer-oriented products. Unfortunately, speaker-independent systems did not provide high accuracy rates in challenging industrial settings, which would force users to repeat themselves or, worse yet, frustrate users to the point where the system becomes unusable.
Another common drawback to speaker-independent systems is that they may have trouble with non-standard speakers – people with heavy accents or speech impediments. And since these systems are not designed to work with user-specific models, they have no way to adjust to challenging users and individual speech patterns.
Serenade Gives the Best of Both Worlds
Serenade provides the advantages of minimal training and adaptation in a single product. What that means is you save 20 minutes or more in initial training, get high accuracy from day one across all users (even challenging users), and don’t have to re-train after getting comfortable with the system. For a DC with a couple of dozen users, every 20 minute time savings equals one eight-hour work day. And in today’s economy every little bit of time and cost-savings matters. More importantly, with industry-best recognition rates, users get confidence in the system from day one and can concentrate on their jobs rather than the technology they are using to do it. At the end of the day, that’s the critical requirement for any voice system.
Share This Story, Choose Your Platform!
Continue Reading
-
 Learn More
Learn MoreOverall Benefits of Cloud-Based Solutions for Your DC Operations
Categories: Voice Technology| Warehouse Management System
-
 Learn More
Learn MoreWhich Mobile Applications Are Right for Your Warehouse Operations?
Categories: In Warehouse Travel Optimization| Order Picking| Voice Technology
-
 Learn More
Learn MoreAre You Up On Warehouse Picking Technology?
Categories: Labor Management| Robotics| Voice Technology

